Beschreibung:
Ziel dieser Bachelorarbeit ist es, ein Tool zur Visualisierung neuronaler Netzwerke zu entwickeln, das aus den Dateiformaten ONNX (Open Neural Network Exchange) oder einer Keras Functional API-Beschreibung neuronale Netzwerke einliest und diese als SVG (Scalable Vector Graphics) darstellt. Die Visualisierung soll dabei nicht nur die Netzstruktur zeigen, sondern auch alle wichtigen Komponenten und Parameter der einzelnen Layer (wie z.B. Anzahl der Neuronen, Aktivierungsfunktionen, Filtergrößen) interaktiv und parametrisierbar darstellen. Insbesondere soll dabei ein klares Verständnis und dem konkreten Ablauf des Prozesses der Datenverarbeitung- und Veränderung aus den Visualisierungen sichtbar werden. Diese können zum Beispiel konkrete Bilder sein.
Aufgabenstellung:
- Recherche: Führen Sie zu Beginn der Arbeit eine umfassende Literaturrecherche durch, um die wichtigsten Komponenten neuronaler Netzwerke zu identifizieren, die in der Visualisierung berücksichtigt werden sollten. Zu diesen Komponenten zählen u.a. Skip Connections, Residual Layers, oder spezifische Architekturen wie U-Net. Recherchieren Sie ebenfalls, welche Tools und Ansätze zur Visualisierung neuronaler Netzwerke bereits existieren und analysieren Sie deren Stärken und Schwächen.
- Eingangsformat: Entwickeln Sie ein Parser-Modul, das ONNX-Dateien und Keras Functional API-Beschreibungen einlesen und in einer strukturierten Form abbilden kann.
- Visualisierung: Entwerfen und implementieren Sie eine Visualisierungslogik, die die Netzarchitektur in Form von SVG-Dateien darstellt. Die Darstellung soll dabei auf klarer und ästhetischer Weise alle relevanten Schichten eines neuronalen Netzwerks, wie Convolutional Layers, Dense Layers, Pooling, Dropout, Skip Connections, etc., wiedergeben.
- Parametrisierung: Die Komponenten der Netzarchitektur sollen interaktiv parametrisierbar sein. Beispielsweise sollen Änderungen der Anzahl von Neuronen oder der Filtergröße in Echtzeit in der SVG-Darstellung reflektiert werden können.
- Erweiterbarkeit: Die Architektur des Tools sollte es ermöglichen, zukünftige Erweiterungen vorzunehmen, z.B. die Integration von anderen Netzwerkbeschreibungen (z.B. PyTorch) oder die Anpassung der Visualisierungsdarstellung für spezielle Netzarten (z.B. RNNs, GANs).
Voraussetzungen:
- Gute Kenntnisse in Python und den Frameworks Keras und ONNX.
- Erfahrung mit der Erstellung von SVG-Grafiken oder ähnlichen Visualisierungsformen.
- Interesse an der Entwicklung von Tools für das maschinelle Lernen.
Ziel der Arbeit:
Das Ergebnis dieser Arbeit soll ein nutzerfreundliches Visualisierungstool sein, das komplexe neuronale Netzwerke auf verständliche Weise darstellt. Der Fokus liegt auf derdetaillierten und parametrisierbaren Visualisierung, die nicht nur die Architektur selbst, sondern auch deren spezifische Parameter und Funktionen greifbar macht. Besonders wichtig ist, dass das Tool auf Basis der Recherche Erkenntnisse aus modernen Netzarchitekturen wie Skip Connections oder U-Net-artigen Strukturen integriert.
Betreuung:
Tobias Arndt, arndt@fh-aachen.de, gerne direkt über WebEx kontaktieren
Ziel der Arbeit ist, eine Self-Organizing Feature Map (SOFM) in pytorch zu implementieren. Dabei soll die Anzahl der Dimensionen frei wählbar sein und die SOFM am Ausgang mit einer Klassifikationsschicht versehen werden.
Die SOFM ist eine bekannte Architektur Neuronaler Netze, die unüberwacht lernen kann und durch Nachtrainieren auch zur Klassifikation geeignet ist. Anders als z.B. Feed-ForwardNetze, wie sie im Deep-Learning eingesetzt werden, kann die SOFM Eingaben nicht nur einer vorgegebenen Klasse zuordnen, sondern bietet auch die Klasse „unbekannt“ als inhärentes Merkmal der Architektur an.
Die Arbeit soll den aktuelle Veröffentlichungen zur SOFM in einer LIteraturrecherche
analysieren und eine SOFM in pytorch so implementieren, dass die Dimensionalität der
SOFM als Hyperparameter vorgegeben werden kann.
Bei vorhandensein eines gelabelten Datensatzes zum Training, soll eine Ausgabeschicht an die SOFM angehangen werden, so dass ein Klassifikator entsteht. Dabei sind die Konventionen von pytorch beim Design der API zu berücksichtigen.
Beschreibung:
Ziel dieser Bachelorarbeit ist es, einen Demonstrator zur Visualisierung neuronaler Netzwerke zu entwickeln. Die Visualisierung soll dabei die aktuellen Aktivierungen der Faltungsebenen und des Feed-Forward Netzes parametrisierbar darstellen („Level-OfDetail“). Der Demonstrator soll dabei ein von einer Kamera aufgenommenes Bild, als Echtzeitvisualisierung auf einem Bildschirm, einschließlich des Zugeordneten Objektes darstellen.
Aufgabenstellung:
- Recherche: Führen Sie zu Beginn der Arbeit eine umfassende Literaturrecherche durch, um den Stand der Technik zur Visualisierung Neuronaler Netze zu erheben. Recherchieren Sie ebenfalls, welche Tools und Ansätze zur Visualisierung neuronaler Netzwerke bereits existieren und analysieren Sie deren Stärken und Schwächen.
- Visualisierung: Entwerfen und implementieren Sie eine Visualisierungslogik, die die Aktivierung der Faltungslayer und des Feed-Forward-Netzes darstellt. Die Darstellung soll dabei auf klarer und ästhetischer Weise alle relevanten Schichten eines neuronalen Netzwerks, wie Convolutional Layers, Dense Layers, Pooling, Dropout, Skip Connections, etc., wiedergeben.
- Parametrisierung: Die Komponenten der Netzarchitektur sollen parametrisierbar sein, Z.B, welche Schichten visualisiert werden oder ob nur ein Teil der Aktivierungen eines Layers dargestellt werden.
- Erweiterbarkeit: Die Architektur des Tools sollte es ermöglichen, zukünftige
Erweiterungen vorzunehmen, z.B. die Integration von Netzwerkbeschreibungen oder die Anpassung der Visualisierungsdarstellung für spezielle Netzarten (z.B. RNNs, GANs).
Voraussetzungen:
- Gute Kenntnisse in Python und den Frameworks Keras und ONNX.
- Interesse an der Entwicklung von Tools für das maschinelle Lernen.
Ziel der Arbeit:
Das Ergebnis dieser Arbeit soll ein nutzerfreundliches Visualisierungstool sein, das komplexe neuronale Netzwerke auf verständliche Weise darstellt. Der Fokus liegt auf der detaillierten und parametrisierbaren Visualisierung, die nicht nur die Architektur selbst, sondern auch deren spezifische Parameter und Funktionen greifbar macht. Besonders wichtig ist, dass das Tool auf Basis der Recherche Erkenntnisse aus modernen Netzarchitekturen wie Skip Connections oder U-Net-artigen Strukturen integriert.
Der Unternehmenspartner stellt Filter für die Automobilindustrie her, die zu sicherheitskritischen Bauteilen gehören. Daraus leiten sich hohe Qualitätsansprüche ab, die derzeit durch manuelle Kontrollen erfüllt werden.
Hierbei ist es besonders wichtig zu beachten, dass der Unternehmenspartner in einem hohen Maß (ungefähr 95%) fehlerfrei produziert. Jeder produzierte Filter wird während des Herstellungsprozess in Form von Zeilen- und Tiefenkameras digital erfasst. Dieser Erfassungsprozess ist hochgradig standartisiert und die Qualität der Aufnahmen unterliegt keinen relevanten Schwankungen. Die Produktionsmenge beläuft sich auf ungefähr 2000 Filter pro Tag.
Um die physische Arbeitslast (manuelle Kontrolle) zu reduzieren können Methoden des bildbasierten Deep Learnings in einer Anomalie-Erkennungs-Formulierung eingesetzt werden, die sehr gute Ergebnisse liefern. Diese basieren in der Regel auf dem Verarbeiten eines kompletten Bildes. Durch die hohe Anzahl an produzierten Filtern und einer zwangsläufigen Verschiebung in der Verteilung von Bildmerkmalen ist eine regelmäßige Anpassung eines solchen Inferenzsystems erforderlich, sodass in der Regel auf vortrainierte Neuronale Netze (unregelmäßig eigens trainierter oder domänen-generalisierter Merkmalsextraktor) zurückgegriffen wird.
Betrachtet man den Aufnahmeprozess über die Zeilenkamera stellt diese Komplett-Bild-Abhängigkeit eine zusätzliche Komplexität dar. Insbesondere für die schnelle Inferenz.
Ziel dieser Arbeit soll es sein Verfahren zu entwickeln und zu vergleichen, die direkt mit den einzelnen Zeilen arbeiten können. Hierbei betrachten wir nicht mehr das Komplett-Bild als 2D Volumen, sondern lediglich die einzelnen Zeilen, die im 1D Raum vorliegen. Obwohl nun deutlich mehr Einzelinferenzen durchgeführt werden müssen, kann dieser Schritt direkt in der Kamera durchgeführt werden, wodurch aufwändige IO Operationen und deren Implikationen stark reduziert werden.
Die hierbei zu verarbeitenden Daten erfüllen Eigenschaften von Zeitreihen, sodass der Schluss naheliegt Algorithmen dieser Klasse zu verwenden – im Spezifischen Algorithen der Zeitreihen-Anomalie-Erkennung. Für die Merkmalsextraktion sollen hierbei Verfahren betrachtet werden, die in Analogie zu der Komplett-Bild-Verarbeitung kein Vortraining erfordern. Aus einer Literaturrecherche und ersten Vorarbeiten im Rahmen einer Seminararbeit kommen Verfahren der Rocket-Klasse in Frage.
Im Rahmen der Arbeit soll eine Anomalie Erkennung auf Rocket-Merkmalen auf den Zeilen der Zeilenbild-Kamera mit Hilfe einer Self-Organizing-Map entwickelt und mit anderen Verfahren verglichen werden. In einem darauf folgenden Schritt soll die Fähigkeit Multivariate-1D Merkmale, die durch die Zusammenführung der Zeilenbild-Kamera mit den Bildern der Tiefenbildkamera entstehen, auf den entwickelten Verfahren untersucht werden.
Anforderungsprofil
Für das genaue Anforderungsprofil nehmen Sie Kontakt auf. Es wird in einem Erstgespräch ermittelt, ob eine für beiden Seiten gewinnbringende Arbeit absolviert werden kann.
Ansprechpartner
Tobias Arndt, arndt@fh-aachen.de
Ausgangssituation
Der Unternehmenspartner stellt Filter für die Automobilindustrie her, die zu sicherheitskritischen Bauteilen gehören. Daraus leiten sich hohe Qualitätsansprüche ab, die
derzeit durch manuelle Kontrollen erfüllt werden.
Der Unternehmenspartner produziert nahezu (ungefähr 95%) fehlerfrei, sodass sehr viele Datenpunkte zu korrekt produzierten Bauteilen vorliegen. Methoden des maschinellen Lernens und der künstlichen Intelligenz stellen vielversprechende Ansätze dar, die nachhaltig dabei helfen können, den manuellen Prüfaufwand zu reduzieren.
Rekontruktionsbasierte Anomalieerkennungsalgorithmen reduzieren den Informationsgehalt des zu betrachtenden Bildes durch verschiedene Methoden und trainieren auf diesen Bildern ein neuronales Netzwerk darauf, diese Bilder wieder so zu rekonstruieren, dass sie möglichst ähnlich zum Original sind. Dadurch dass auf möglichst anomalie-freien Bildern trainiert wird, sollen Anomalien mit größeren Rekonstruktionsfehlern erstellt werden und damit aussortiert werden.
Rekonstruktionsalgorithmen unterscheiden sich vor allem durch die Methodik, den Informationsgehalt zu reduzieren. Dies wird beispielsweise bereits durch Rauschen, Ausschneiden und Tauschen von Bildteilen sowie Projektionen in kleinere Dimensionen erzielt.
Ziel
Ziel dieser Arbeit ist es aufzulisten, welche Methodiken zur Informationssreduktion von Bildern für rekonstruktionsbasierte Anomalieerkennung in Frage kommen, ausgewählte davon zu implementieren und diese mit dem Stand der Forschung so wie untereinander zu vergleichen und zu evaluieren.
Pythonkenntnisse (insbesondere Pytorch) sowie Vorkenntnisse über neuronale Netzwerke
sind von Vorteil.
Aufgaben
- Untersuchung der Einsatzmöglichkeiten von Informationssreduktionen von Bildern für rekonstruktionsbasierte Anomalieerkennung
- Implementierung und Training von diesen Anomaliedetektoren auf unterschiedlichen Datensätzen
- Anpassungen/Optimierung der Modelle und Evaluation
Dein Benefit
- Lernen von immer wichtiger werdenden Technologien, in einem Umfeld ohne technische Limitierungen. (Arbeit auf Cluster mit den leistungsfähigsten Grafikkarten zur Zeit der Ausschreibung)
- Kenntnisse über eine breite Anzahl von aktuellen Ansätzen des maschinellen Lernens erlernen
- Möglichkeit Teil einer Veröffentlichung zu werden
Ansprechpartner
Matteo Tschesche
E-Mail: tschesche@fh-aachen.de
Ausgangssituation
Der Unternehmenspartner stellt Filter für die Automobilindustrie her, die zu sicherheitskritischen Bauteilen gehören. Daraus leiten sich hohe Qualitätsansprüche ab, die derzeit durch manuelle Kontrollen erfüllt werden.
Der Unternehmenspartner produziert nahezu (ungefähr 95%) fehlerfrei, sodass sehr viele Datenpunkte zu korrekt produzierten Bauteilen vorliegen.
Methoden des maschinellen Lernens und der künstlichen Intelligenz stellen vielversprechende Ansätze dar, die nachhaltig dabei helfen können, den manuellen Prüfaufwand zu reduzieren.
Rekontruktionsbasierte Anomalieerkennungsalgorithmen reduzieren den Informationsgehalt des zu betrachtenden Bildes durch verschiedene Methoden (beispielsweise durch Rauschen, Ausschneiden und Tauschen von Bildteilen) und trainieren auf diesen Bildern ein neuronales Netzwerk darauf, diese Bilder wieder so zu rekonstruieren, dass sie möglichst ähnlich zum Original sind. Dadurch dass auf möglichst anomalie-freien Bildern trainiert wird, sollen Anomalien mit größeren Rekonstruktionsfehlern erstellt werden und damit aussortiert werden.
Diese rekonstruierten Bilder unterscheiden sich für das menschliche Auge oft gut vom Originalbild bei Anomalien im Vergleich zu normalen Bildern und dennoch werden solche Bilder oft als Anomalie markiert. Das liegt an hohen Varianzen der Pixel im Bild an sich und an einfachen Schwellenwertverfahren mit denen der Unterschied berechnet wird.Die Nutzung von Methoden des machinellen Lernens auf diesen rekonstruierten Bildern bietet die Möglichkeit bessere Ergebnisee für die Anomalieerkennung zu gewinnen.
Ziel
Ziel dieser Arbeit ist es sich mit bereits implementierten rekonstruktionsbasierten Anomalieerkenungsmethoden auseinanderzusetzen und darauf aufbauend Methoden zu recherchieren, die benutzt werden können um die Ergebnisse der Anomalieerkennung auf diesen Bildern zu erhöhen.
Das beinhaltet vor allem die Kombination mehrerer Bildern und das Lernen von Klassifikatoren. Diese Verfahren der Klassifikation sollen evaluiert werden und Rückschlüsse ebenfalls auf die Nutzung verschiedener rekonstruktionsbasierter Ansätze ziehen.
Pythonkenntnisse (insbesondere Pytorch) sowie Vorkenntnisse über neuronale Netzwerke
sind von Vorteil.
Aufgaben
- Untersuchung der Einsatzmöglichkeiten von Klassifikationsmethoden auf rekonstruierten Bildern für die Anomalieerkennung
- Implementierung, Einbindung und Training von diesen Klassifikatoren auf unterschiedlichen rekonstruktionsbasierten Anomalieerkennungsalgorithen und auf unterschiedlichen Datensätzen
- Anpassungen/Optimierung der Modelle und Evaluation
Dein Benefit
- Lernen von immer wichtiger werdenden Technologien, in einem Umfeld ohne technische Limitierungen. (Arbeit auf Cluster mit den leistungsfähigsten Grafikkarten zur Zeit der Ausschreibung)
- Kenntnisse über aktuelle Ansätze neuronaler Netzwerke für Klassifikationsprobleme
erlernen - Möglichkeit Teil einer Veröffentlichung zu werden.
Ansprechpartner
Matteo Tschesche
E-Mail: tschesche@fh-aachen.de
Overview: We are seeking a motivated bachelor’s or master’s student for a thesis on 3D geometry reconstruction and parameter extraction of helical blades using a vision system. The project involves merging point clouds from different poses using a structured light or RGB-D camera to create a complete 3D model. Challenges like missing data due to reflections and lighting variations will be addressed using machine learning techniques. Key parameters, such as radius, pitch, and twist of the blade will be extracted from the processed point cloud. The approach will be tested in simulation before evaluation on real hardware.
Key Objectives:
- Point Cloud Merging: To explore different approaches to align and merge multiple point cloud datasets captured from different camera poses to create a unified and accurate 3D representation of the helical blade.
- Handling Missing Data and Geometry Reconstruction: Addressing the issue of missing or incomplete data points in the point cloud caused by reflections from metallic surfaces and variations in ambient lighting. This step involves applying machine learning techniques, (supervised/ unsupervised), to reconstruct missing features.
- Parameter Extraction: Extract key parameters of the helical blade, such as the radius, pitch, and twist from the reconstructed model. This step will involve applying geometric analysis techniques to accurately quantify the properties of the blade and compare them with the desired specifications.
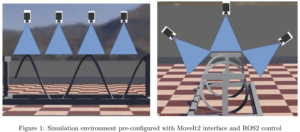
Requirements:
- Background in robotics, computer vision, or machine learning
- Experience with ROS, Python, or C++ is a plus
- Familiarity with point cloud processing (PCL, Open3D)
- Basic knowledge of geometric analysis and parameter extraction from 3D models
What Will You Gain:
- Hands-on experience with industrial robotics and vision-based measurement
- Opportunity to implement the solution on real-time hardware in a production environment
- Brief introduction to setting up a simulation environment using Webots
Interested? Contact us at borse@fh-aachen.de for more details!
Overview: We are looking for a motivated bachelor/master’s thesis student to work on a project focused on coverage path planning for measuring the parameters of helical blades using a robotic vision system. The thesis will involve motion planning using sequential sampling to ensure complete exposure of the object for accurate measurement. The project will leverage a Universal Robot (UR) equipped with a structured light or RGB-D camera to capture 3D data of metallic helix blades. Additionally, the student will tackle challenges in data reconstruction using a machine-learning approach to fill in missing features and improve the overall model.
The approach can be implemented and tested in a preconfigured simulation environment, as depicted in the image below, followed by a final evaluation on real-time hardware with a similar setup.
Key Objectives:
- Coverage Path Planning: A motion planning strategy utilizing the MoveIt2 ROS pipeline to plan the robot’s trajectory and ensure complete and systematic coverage of a helical blade. This approach ensures maximized exposure, accounting for factors like the robot’s reach and the camera’s field of view to avoid gaps in the data.
- Point Cloud Fusion: The process of merging multiple point cloud data sets captured at different poses of the robotic arm using transformations. This fusion creates an accurate 3D model of the helical blade, capturing all essential surface details and geometry.
- Handling Missing Data and Geometry Reconstruction: Addressing the issue of missing or incomplete data points in the point cloud caused by reflections from metallic surfaces and variations in ambient lighting. This step involves applying machine learning techniques, (supervised/unsupervised), to reconstruct missing features.
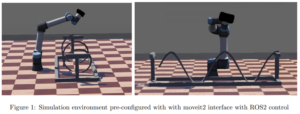
Requirements:
- Background in robotics, computer vision, or machine learning
- Experience with ROS, Python, or C++ is a plus
- Familiarity with point cloud processing (PCL, Open3D)
What You Will Gain:
- Hands-on experience with industrial robotics and vision-based measurement
- Gained knowledge in motion planning and coverage path planning using the MoveIt2 pipeline
- Possibility to implement the solution on real-time hardware in a production environment
- Brief introduction to setting up a simulation environment using Webots
Interested? Contact us at borse@fh-aachen.de for more details!
Ausgangssituation:
CanControls ist ein innovatives Software-Unternehmen mit Schwerpunkten im Bereich der Echtzeit-Bildverarbeitung, Computer Vision und videobasierten Szenenanalyse.
Von uns entwickelte Technologien kommen in der der Automobilindustrie, der Luft- und Raumfahrt, der Medizintechnik, dem Straßenwesen und der Unterhaltungselektronik zum Einsatz.
Digitale Zwillinge unserer Systeme erlauben es, die Bildgebung/Bildverarbeitung in existierenden Anwendungen zu optimieren, sowie neue Anwendungsfelder digital zu bewerten.
Dafür ist eine möglichst realitiätsnahe Bildsynthese essentiell.
Moderne Methoden der generativen künstlichen Intelligenz stellen hierfür einen vielversprechenden Ansatz dar.
Deine Aufgaben und Vorkenntnisse:
Moderne Verfahren der Bildsynthese berücksichtigen ausschließlich den sichtbaren Wellenlängenbereich in Form von RGB-Bildern.
Ziel dieser Arbeit ist es auf Stable Diffusion basierende Bildsynthese für RGB auf den nicht sichtbaren Wellenlängenbereich zu übertragen.
1. Einarbeitung in Stable Diffusion
2. Recherche gängiger Methoden der „Personalisierung“ etablierter text-to-image Modelle (Textual Inversion, DreamBooth, LoRa, HyperNetworks, etc.)
3. Bewertung dieser Methoden im Kontext unserer proprietären Bilddaten
Vorkenntnisse in Python sowie in gängigen Deep-Learning Bibliotheken (TensorFlow/PyTorch) sind wünschenswert.
Fließendes Englisch in Wort und Schrift ist erforderlich.
Deine Benefits:
1. Du wirst Teil eines internationalen Teams mit Sitz im Zentrum von Aachen
2. Lernen von State-of-the-Art Technologien, in einem Umfeld ohne technische Limitierungen. (Arbeit auf Cluster mit den leistungsfähigsten Grafikkarten zur Zeit der
Ausschreibung)
3. Persönliche Betreuung während des Praktikums.
4. Möglichkeit Teil einer Veröffentlichung auf einer Top-Konferenz zu werden (CVPR, ICCV, ECCV, NeurIPS ).
Ansprechpartner:
luttermann@cancontrols.com
Dr. Tarek Luttermann


Informationen zum Unternehmen:
Die SBS Ecoclean Gruppe entwickelt, produziert und vertreibt zukunftsorientierte Anlagen, Systeme und Services für die industrielle Teilereinigung und Entfettung, Ultraschall Feinstreinigung, Hochdruck Wasserstrahlentgraten sowie für die Oberflächenvorbereitung und -behandlung.
Unsere Kunden kommen aus unterschiedlichsten Branchen der Bauteil- und Präzisionsfertigung – wie z.B. Luft- und Raumfahrt, Medizintechnik, Automobil- und Zuliefer-, Hightech-, Halbleiter- und Hochvakuumindustrie, Präzisionsoptik, Mikro- und Feinwerk-, sowie Verbindungstechnik und die Uhren- & Schmuck-Industrie.
Ein weiterer Tätigkeitsbereich ist die Entwicklung und Produktion von alkalischen Elektrolysesystemen für die Erzeugung von grünem Wasserstoff. Als globaler Systemintegrator bieten wir Industrie, Mobilität und Kommunen eine alternative Energiequelle und unterstützen sie so auf dem Weg in eine nachhaltige Zukunft.
Übersicht:
Im Zuge des PerformanceLine-Projektes soll die Optimierung eines neuen Korbs mit zugeordnetem Rezept und flexiblen Prozesszeiten vorangetrieben werden. Dabei stehen die Implementierung einer Online-Prozesszeitveränderung und die Gestaltung eines Portals mit Be-/Entlade-Sequenzen im Fokus.
![]()
Recommender System für Produktionssteuerung:
Bachelor- / Masterarbeit:
- Vorschlag für den Bediener für das nächste zeiteffektivste Rezept / Werkstück => Max. Durchsatz
Masterarbeit:
- Generieren der Fahrbefehle für das Portal unter Einhaltung der festen Prozesszeiten bzw. im zeitlichen Rahmen der flexiblen Prozesszeiten unter in der Maschine befindlichen Körbe / Rezepte
- Maximieren des Durchsatzes unter Berücksichtigung der realen Beladung mit Losgröße „1“.
Ansprechpartner:
Ecoclean GmbH
Rüdiger Fritzen
E-Mail: ruediger.fritzen@ecoclean-group.net
Telefon: +49 2472 83-243
www.ecoclean-group.net
Informationen zum Unternehmen:
Die SBS Ecoclean Gruppe entwickelt, produziert und vertreibt zukunftsorientierte Anlagen, Systeme und Services für die industrielle Teilereinigung und Entfettung, Ultraschall Feinstreinigung, Hochdruck Wasserstrahlentgraten sowie für die Oberflächenvorbereitung und -behandlung.
Unsere Kunden kommen aus unterschiedlichsten Branchen der Bauteil- und Präzisionsfertigung – wie z.B. Luft- und Raumfahrt, Medizintechnik, Automobil- und Zuliefer-, Hightech-, Halbleiter- und Hochvakuumindustrie, Präzisionsoptik, Mikro- und Feinwerk-, sowie Verbindungstechnik und die Uhren- & Schmuck-Industrie.
Ein weiterer Tätigkeitsbereich ist die Entwicklung und Produktion von alkalischen Elektrolysesystemen für die Erzeugung von grünem Wasserstoff. Als globaler Systemintegrator bieten wir Industrie, Mobilität und Kommunen eine alternative Energiequelle und unterstützen sie so auf dem Weg in eine nachhaltige Zukunft.
Übersicht:
Im Zuge des PerformanceLine-Projektes soll die Optimierung eines neuen Korbs mit zugeordnetem Rezept und flexiblen Prozesszeiten vorangetrieben werden. Dabei stehen die Implementierung einer Online-Prozesszeitveränderung und die Gestaltung eines Portals mit Be-/Entlade-Sequenzen im Fokus.
![]()
KI-Planungssystem für optimale Prozessdurchführung:
Bachelor- / Masterarbeit Maschinenkonfigurationstool:
- Anhand der definierten Taktzeitvorgaben / Durchsatzmenge, Rezepten, Stückzahlen und der Beladereihenfolge
- Bestimmung der Anzahl der Portale zur Erreichung der Vorgaben
- Bestimmung der Anzahl der notwendigen Mehrfach-Prozessstationen zur Erreichung der Vorgaben
Ansprechpartner:
Ecoclean GmbH
Rüdiger Fritzen
E-Mail: ruediger.fritzen@ecoclean-group.net
Telefon: +49 2472 83-243
www.ecoclean-group.net